- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
智能语音转写,简单来说,是将语音信号转化为文字信息的技术.其背后蕴含着复杂而精妙的原理.它的运行基础是声学模型和语言模型.声学模型负责分析语音的声学特征,例如音素的发音方式、音高、音色等.语言模型则像是一本巨大的语料库,包含着丰富的语言知识和语法规则.当语音输入进来时,系统首先对声学特征进行提取,然后与声学模型进行比对,初步确定可能的语音内容.接着,语言模型对这些初步结果进行评估,根据语法和语义的合理性进行筛选和调整,较终输出准确的文字.例如,当听到“现在天气很好”这句话时,系统会通过声学分析识别出各个音素,再由语言模型判断出这是符合正常语义的表达,从而完成转写.语音转写产品能将人类语音信号实时或离线转化为可编辑文字,提升信息处理效率。广州文字识别语音转写怎么样

针对方言与不同口音的识别难题,语音转写产品研发了专项适配技术。技术层面,通过构建多语种、多方言语音数据库,涵盖粤语、四川话、东北话等主流方言及各地方口音普通话,采用迁移学习算法,让模型在通用语音识别基础上,快速适配特定方言与口音特征;同时,引入口音自适应训练功能,用户可上传少量带口音的语音样本,模型通过学习调整识别参数,提升个人语音转写准确率。部分产品还推出方言转写专项版本,针对特定地区用户需求,优化方言词汇、语法识别逻辑,例如识别粤语中的 “唔该”“系啊” 等常用词汇,解决方言沟通场景下的转写痛点,拓宽产品适用人群范围。上海智能语音转写有什么功能语音转写工具可对不同风格的语音进行适配,如正式演讲或日常对话。
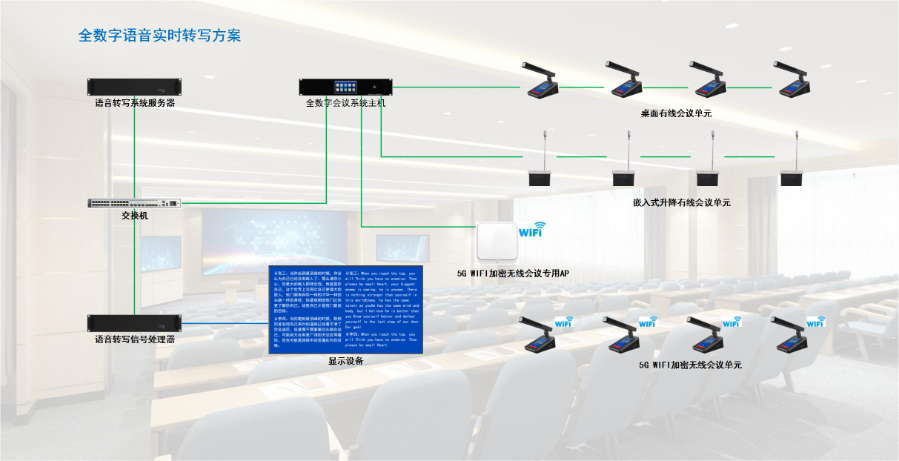
为帮助新手快速掌握语音转写产品使用方法,官方通常提供完善的入门指南并梳理常见问题解决方案。入门指南包含三步重心操作:第一步,根据使用场景选择模式(实时转写 / 离线转写 / 音频导入),会议场景推荐实时转写,录音整理则选音频导入;第二步,完成基础设置,如选择语言类型、开启降噪功能,若涉及专业内容可提前导入自定义词典;第三步,熟悉编辑工具,掌握标注重点、添加注释、导出文档的操作。常见问题解决方案涵盖:转写准确率低时,检查是否开启降噪、是否适配当前口音,建议在安静环境重新录制;导出文档格式错乱时,更新产品版本或尝试换用其他导出格式(如从 PDF 换为 Word);云端同步失败时,检查网络连接或重新登录账号,确保设备处于同一账号下。
语音转写产品在法律行业形成深度适配的应用方案,满足专业场景需求。在庭审场景中,产品支持 “庭审专属模式”,可精细识别法官、律师、当事人等不同角色语音,自动标注发言主体,转写内容实时同步至庭审记录系统,同时支持与庭审录像联动,点击文字即可定位对应录像片段,便于后续庭审回顾与证据核对;在律师办公场景,产品内置法律专业词典,涵盖 “诉讼时效”“管辖权” 等海量法律术语,确保合同谈判、案件讨论的语音转写准确无误,转写后的文档可直接生成标准法律文书格式(如起诉状、辩护词模板),律师只需补充关键信息即可使用;此外,产品还支持法律语音文件加密存储,设置访问权限分级,保障案件信息安全,助力法律工作高效开展。语音转写的表情符号匹配功能根据语音情绪推荐表情,让内容表达更生动。

语音转写产品具备高精细识别能力,通过多重技术手段确保不同场景下的转写准确性,这是其赢得用户信任的关键优点。一方面,产品依托大规模语料库与深度学习模型,通用场景下转写准确率稳定在 95% 以上,能精细识别日常对话、专业演讲中的常用词汇与语法逻辑;另一方面,针对特殊场景推出专项优化,如面对专业领域(法律、医疗、科技),内置百万级行业术语词典,可自动识别 “诉讼时效”“区块链共识机制” 等专业词汇,避免术语误写;针对口音与方言,通过口音自适应训练与方言语料库优化,能适配东北话、粤语等主流方言及各地方口音普通话,减少因发音差异导致的识别偏差,确保转写内容与原始语音高度一致。老年用户友好版语音转写放大按钮与字体,支持方言语音控制,降低使用门槛。南京多语言识别语音转写价格
语音转写技术能将方言语音准确地转写成对应的文字,保留地域特色。广州文字识别语音转写怎么样
语音转写产品具备全场景适配优势,能灵活满足不同行业、不同人群的多样化使用需求,打破场景局限。在职场领域,适配会议记录、客户访谈、项目汇报等场景,支持多 speaker 分离、重点标注功能;在教育领域,适配课堂教学、学术讲座、学生笔记场景,提供知识点提取、双语对照功能;在生活领域,适配家庭录音整理、自媒体口播脚本创作、老人语音记事场景,支持轻量化操作与离线使用;在专业领域,还能深度适配医疗病历记录、法律庭审记录、物流调度沟通等垂直场景,提供符合行业规范的定制化功能。无论是室内安静环境还是户外嘈杂环境,无论是短时长语音还是数小时长音频,产品都能稳定发挥作用,真正实现 “全场景可用”。广州文字识别语音转写怎么样

语音转写产品针对儿童教育场景,开发趣味化、引导式转写功能,适配儿童学习习惯。在亲子阅读场景,产品支持 “绘本语音转写 + 互动答问”,家长朗读绘本时,系统实时转写文字并同步显示绘本插图,转写完成后自动生成与内容相关的趣味问题(如 “小熊现在去了哪里呀”),帮助儿童加深内容理解;在口语练习场景,产品内置儿童发音评测模块,转写儿童英语、语文口语表达时,同步分析发音准确度、语调流畅度,生成可视化评分报告,标注 “发音不准词汇” 并提供标准读音示范,助力儿童提升口语能力;此外,产品还支持家长管控功能,可设置每日使用时长、内容过滤规则,避免儿童接触不适宜内容,打造安全的学习辅助环境。语音转写产品能将人类...
- 广州多角色语音转写好用吗 2026-02-26
- 文字识别语音转写系统 2026-02-26
- 长沙智能语音转写软件 2026-02-26
- 法院语音转写同时转写 2026-02-26
- 北京文字识别语音转写软件 2026-02-26
- 广州AI智能语音转写价格 2026-02-26
- 音频转文字语音转写怎么样 2026-02-26
- 长沙智能翻译语音转写云平台 2026-02-26
- 长沙多语言识别语音转写价格 2026-02-26
- 北京角色分离语音转写好用吗 2026-02-26


- 长沙文字识别语音转写报价 2026-02-26
- 广州自动记录语音转写软件 2026-02-25
- 南京多角色语音转写价格 2026-02-25
- 广州声音转文字语音转写怎么样 2026-02-25
- 上海文字识别语音转写价格 2026-02-25
- 长沙会议纪要语音转写字幕 2026-02-25

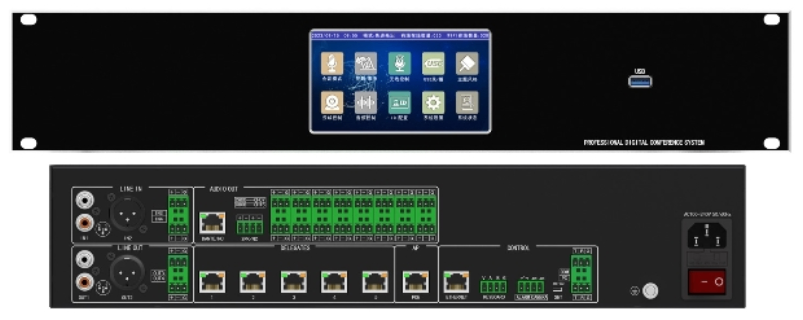


- 北京文字识别语音转写软件 02-26
- 广州AI智能语音转写价格 02-26
- 音频转文字语音转写怎么样 02-26
- 长沙智能翻译语音转写云平台 02-26
- 长沙多语言识别语音转写价格 02-26
- 北京角色分离语音转写好用吗 02-26
- 南京声音转文字语音转写云平台 02-26
- 智能翻译语音转写故障排除 02-26
- 广州语音转写软件系统 02-26
- 北京法院语音转写同时翻译 02-26