- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
智能语音转写,简单来说,是将语音信号转化为文字信息的技术.其背后蕴含着复杂而精妙的原理.它的运行基础是声学模型和语言模型.声学模型负责分析语音的声学特征,例如音素的发音方式、音高、音色等.语言模型则像是一本巨大的语料库,包含着丰富的语言知识和语法规则.当语音输入进来时,系统首先对声学特征进行提取,然后与声学模型进行比对,初步确定可能的语音内容.接着,语言模型对这些初步结果进行评估,根据语法和语义的合理性进行筛选和调整,较终输出准确的文字.例如,当听到“现在天气很好”这句话时,系统会通过声学分析识别出各个音素,再由语言模型判断出这是符合正常语义的表达,从而完成转写.语音转写对于广播剧制作来说,是一种方便的剧本整理方式。广州实时语音转写软件系统

语音转写产品在用户体验优化上注重细节打磨,提升使用便捷性与舒适度。在交互设计上,推出 “场景化快捷入口”,用户打开产品后,可直接选择 “会议”“采访”“课堂” 等场景,系统自动匹配对应参数(如会议场景默认开启多 speaker 分离,课堂场景默认开启重点标注),无需手动调整;在内容编辑上,新增 “智能纠错建议” 功能,转写完成后,系统自动识别疑似错误内容(如同音不同字、语法问题)并标注,点击标注即可查看修正建议,同时支持批量替换相同错误,减少逐字核对时间;在视觉体验上,提供多套主题皮肤(如简约白、护眼黑、商务蓝),支持字体大小、行间距自定义,适配不同用户阅读习惯,长时间使用不易视觉疲劳,从交互、编辑、视觉多维度提升整体使用体验。文字识别语音转写怎么样企业定制版语音转写可添加企业LOGO,设计专属界面,强化品牌辨识度。

展望未来,智能语音转写有着无限的发展潜力.随着人工智能技术的进一步深化,语音转写的准确率有望继续提高,能够更加精细地处理各种复杂语音情况,包括极快语速、高度口语化和夹杂大量方言的表述等.在用户体验方面,它将变得更加智能和个性化.系统可以根据用户的习惯和偏好进行定制化的识别和转写,例如,针对特定用户经常使用的词汇进行优化识别.智能语音转写技术也可能会与其他新兴技术如虚拟现实、增强现实等相结合,创造出更加沉浸式的交互体验.例如,在虚拟现实会议场景中,语音转写能够实时将参与者的对话转化为文字,并与虚拟场景中的内容进行交互展示.可以预见,在未来生活的各个角落,智能语音转写都将成为人们高效沟通和处理信息的得力助手.
不错语音转写产品注重用户社群运营,构建完善的用户服务生态。在社群运营上,建立官方用户交流群(如按行业分类的职场群、教育群、法律群),定期组织线上分享活动,邀请熟练用户讲解使用技巧(如 “如何提升专业领域转写准确率”“高效整理会议记录方法”),产品团队也会在群内收集需求、解答疑问,增强用户粘性;在服务延伸上,推出 “专属顾问” 服务,付费会员可享受一对一专属顾问指导,针对个性化需求(如企业系统集成、特殊场景适配)提供定制化解决方案,同时提供定期使用报告,分析用户转写习惯,给出效率提升建议;此外,社群内还会开展用户共创活动,邀请用户参与新产品功能测试,收集反馈并优化,让用户参与产品成长,提升用户认同感。学术讲座转写自动标注参考文献格式,辅助科研人员整理资料撰写论文。

不错的语音转写产品拥有完善的售后服务体系,同时提供多元化用户反馈渠道。售后服务包含:7×24 小时在线客服,通过文字、语音、视频三种方式解答问题,复杂操作问题可远程协助;定期产品培训,线上直播讲解新功能使用方法、高级技巧,回放视频可随时查看;故障维修服务,若因产品问题导致数据丢失,技术团队可协助恢复(需在数据留存期内)。用户反馈渠道涵盖:产品内 “意见反馈” 入口,支持文字描述 + 截图 / 录屏提交;官方社群(微信群、QQ 群),用户可与其他使用者交流经验,也能直接向产品经理提建议;官方公众号 / 微博,定期收集热门反馈并公示优化进度,例如用户普遍反映 “方言转写准确率待提升”,后续版本会重点优化该功能,让用户参与产品迭代过程。语音转写技术可识别语音中的停顿节奏,并在转写结果中合理分段。北京角色分离语音转写好用吗
跨境会议中,语音转写生成双语对照文档,参会者可自主切换目标语言。广州实时语音转写软件系统
语音转写产品优化隐私权限管理,提供更精细化的权限设置,保障用户数据安全。在数据访问权限上,支持 “角色权限分级”,企业用户可设置 “管理员 - 普通用户 - 查看用户” 三级权限,管理员可管理所有转写文档,普通用户可查看自己创建的文档,查看用户能浏览指定文档;在数据使用权限上,新增 “数据授权开关”,用户可自主选择是否允许产品使用匿名转写数据优化模型,关闭开关后,所有数据用于个人转写服务,不参与模型训练;在设备授权管理上,支持 “登录设备管理”,用户可查看所有登录过账号的设备,一键下线陌生设备,同时设置 “设备信任名单”,信任设备可同步转写数据,降低账号被盗用导致的数据泄露风险。广州实时语音转写软件系统
语音转写产品的精细性依赖三大重心技术:声学模型、语言模型与语音活动检测(VAD)。声学模型负责将语音信号转化为音素序列,通过海量语音数据训练,能区分不同口音、语速及背景噪音;语言模型基于语法规则与语义逻辑,优化文字组合合理性,例如避免 “形式” 误写为 “形势”;VAD 技术则可自动识别语音片段与静音时段,剔除无效信息,提升转写效率。部分不错产品还融入实时降噪、多 speaker 分离技术,在嘈杂会议或多人对话场景中,仍能保持清晰转写效果,技术迭代方向正朝着 “低资源语种适配”“跨模态信息融合” 持续推进。语音转写产品可生成带时间戳的文档,点击文字能回溯对应语音片段,方便核对。北京无纸化语音转...
- 南京无纸化语音转写软件系统 2026-03-14
- 北京自动翻译语音转写作用 2026-03-14
- 上海会议纪要语音转写故障排除 2026-03-14
- 自动翻译语音转写售后维护 2026-03-14
- 广州角色分离语音转写云平台 2026-03-14
- 北京国产化语音转写有什么功能 2026-03-14
- 南京全数字语音转写有什么功能 2026-03-14
- 南京法院语音转写故障排除 2026-03-14
- 北京多角色语音转写系统 2026-03-14
- 长沙多角色语音转写同时翻译 2026-03-14



- 广州语音转写云平台 2026-03-14
- 广州法院语音转写作用 2026-03-13
- 广州文字识别语音转写哪家好 2026-03-13
- 智能语音转写故障排除 2026-03-13
- 北京多角色语音转写好用吗 2026-03-13
- 南京多角色语音转写价格 2026-03-13

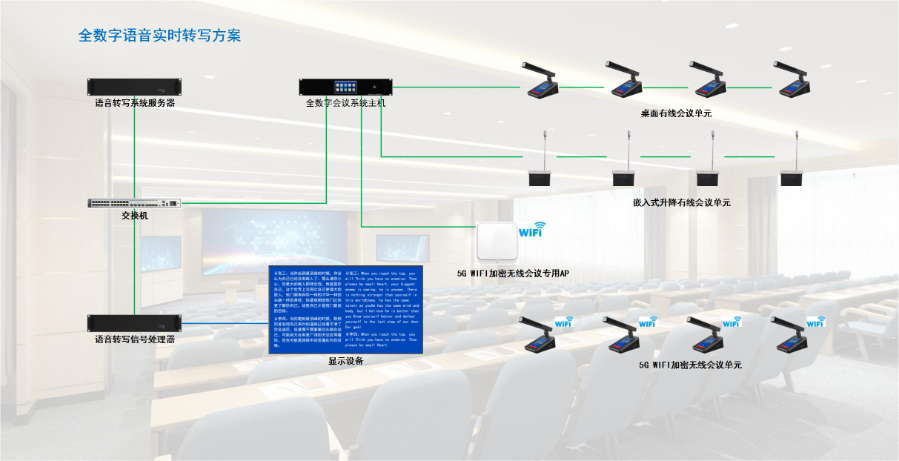

- 广州角色分离语音转写云平台 03-14
- 北京国产化语音转写有什么功能 03-14
- 南京全数字语音转写有什么功能 03-14
- 南京法院语音转写故障排除 03-14
- 北京多角色语音转写系统 03-14
- 长沙多角色语音转写同时翻译 03-14
- 北京文字识别语音转写有什么功能 03-14
- 上海国产化语音转写哪家好 03-14
- 北京多语言识别语音转写有什么功能 03-14
- 长沙庭审语音转写好用吗 03-14