尽管瑕疵检测技术取得了长足进步,但仍存在若干瓶颈。首先,“数据饥渴”与“零缺陷”学习的矛盾突出:深度学习需要大量缺陷样本,但现实中追求的目标恰恰是缺陷极少出现,如何利用极少量的缺陷样本甚至用正常样本进行训练(如采用自编码器、One-Class SVM进行异常检测)是一个热门研究方向。其次,模型的泛化...
瑕疵检测系统基本参数
- 品牌
- 熙岳智能
- 型号
- 瑕疵检测系统
- 适用范围
- 零件瑕疵显微检测系统
- 产地
- 中国南京
- 厂家
- 南京熙岳智能科技有限公司
瑕疵检测系统企业商机
早期的瑕疵检测系统严重依赖传统的机器视觉技术。这类方法通常基于预设的规则和数学模型。例如,通过像素值的阈值分割来区分背景与前景,利用边缘检测算子(如Sobel、Canny)来定位轮廓异常,或通过傅里叶变换分析纹理的周期性是否被破坏。这些技术在处理光照稳定、背景简单、缺陷模式固定的场景(如检测玻璃瓶上的明显裂纹或PCB板的缺件)时非常有效,且具有算法透明、计算资源需求相对较低的优势。然而,其局限性也十分明显:系统柔性差,任何产品换型或新的缺陷类型出现都需要工程师重新设计和调试算法;对于复杂、微弱的缺陷,或者背景纹理多变的情况(如皮革、织物、复杂装配件),传统算法的鲁棒性往往不足。正是这些挑战,推动了人工智能,特别是深度学习技术在瑕疵检测领域的**性应用。以卷积神经网络(CNN)为深度学习模型,能够通过海量的标注数据(包含大量正常样本和各类缺陷样本)进行端到端的学习,自动提取出区分良品与瑕疵的深层、抽象特征。这种方法不再依赖于人工设计的特征,对复杂、不规则的缺陷具有极强的识别能力,极大地提升了系统的适应性和检测精度,是当前技术发展的主流方向。检测精度和速度之间往往需要根据实际需求取得平衡。南京榨菜包瑕疵检测系统案例

在深度学习普及之前,瑕疵检测主要依赖于一系列经典的数字图像处理算法。这些算法通常遵循一个标准的处理流程:图像预处理、特征提取与分类决策。预处理包括灰度化、滤波(如高斯滤波去噪、中值滤波去椒盐噪声)、图像增强(如直方图均衡化以提高对比度)等,旨在改善图像质量。特征提取是关键步骤,旨在将图像转换为可量化的特征向量,常用方法包括:基于形态学的操作(如开运算、闭运算)检测颗粒或孔洞;边缘检测算子(如Sobel、Canny)寻找划痕或边界缺损;纹理分析算法(如灰度共生矩阵GLCM、局部二值模式LBP)鉴别织物或金属表面的纹理异常;基于阈值的分割(如全局阈值、自适应阈值)分离前景与背景;以及斑点分析、模板匹配(归一化互相关)等。通过设定规则或简单的分类器(如支持向量机SVM)对提取的特征进行判断。这些传统方法在场景可控、光照稳定、瑕疵特征明显且与背景差异大的应用中表现良好,且具有算法透明、可预测、计算资源要求相对较低的优点。然而,其局限性也显而易见:严重依赖经验进行特征工程,算法泛化能力差,对光照变化、产品位置轻微偏移、复杂背景或新型未知瑕疵的鲁棒性不足,难以应对日益增长的检测复杂性需求。上海铅酸电池瑕疵检测系统制造价格遮挡和复杂背景是实际应用中需要解决的难题。

高分辨率相机是瑕疵检测关键硬件,为缺陷识别提供清晰图像基础。没有清晰的图像,再先进的算法也无法识别缺陷,高分辨率相机是捕捉细微缺陷的 “眼睛”。根据检测需求不同,相机分辨率需合理选择:检测电子元件的微米级缺陷(如芯片引脚变形),需选用 1200 万像素以上的相机,确保图像像素精度≤1μm;检测普通塑料件的毫米级缺陷(如表面划痕),500 万像素相机即可满足需求。高分辨率相机还需搭配光学镜头,减少畸变(畸变率≤0.1%),确保图像边缘清晰。例如检测手机摄像头模组时,1200 万像素相机可清晰拍摄模组内部的微小灰尘(直径≤0.05mm),为算法识别提供清晰图像,若使用低分辨率相机,可能因图像模糊漏检灰尘,导致摄像头拍照出现黑点,影响产品质量。
深度学习赋能瑕疵检测,通过海量数据训练,提升复杂缺陷识别能力。传统瑕疵检测算法对规则明确的简单缺陷识别效果较好,但面对形态多样、边界模糊的复杂缺陷(如金属表面的不规则划痕、纺织品的混合织疵)时,易出现误判、漏判。而深度学习技术通过构建神经网络模型,用海量缺陷样本进行训练 —— 涵盖不同光照、角度、形态下的缺陷图像,让模型逐步学习各类缺陷的特征规律。训练完成后,系统不能快速识别已知缺陷,还能对未见过的新型缺陷进行初步判断,甚至自主优化识别逻辑。例如在汽车钣金检测中,深度学习模型可区分 “碰撞凹陷” 与 “生产压痕”,大幅提升复杂场景下的缺陷识别准确率。随着技术进步,瑕疵视觉检测正朝着更智能、更柔性的方向发展。
为了解决深度学习对大量标注数据的依赖问题,无监督和弱监督学习方法在瑕疵检测领域受到关注。无监督异常检测的思想是:使用“正常”(无瑕疵)样本进行训练,让模型学习正常样本的数据分布或特征表示。在推理时,对于输入图像,模型计算其与学习到的“正常”模式之间的差异(如重构误差、特征距离等),若差异超过阈值,则判定为异常(瑕疵)。典型方法包括自编码器及其变种(如变分自编码器VAE)、生成对抗网络GAN(通过训练生成器学习正常数据分布,鉴别器辅助判断异常)、以及基于预训练模型的特征提取结合一类分类(如支持向量数据描述SVDD)。这些方法避免了收集各种罕见瑕疵样本的困难,特别适用于瑕疵形态多变、难以预先穷举的场景。弱监督学习则更进一步,它利用更容易获得但信息量较少的标签进行训练,例如图像级标签(*告知图像是否有瑕疵,但不告知位置)、点标注或涂鸦标注。通过设计特定的网络架构和损失函数,模型能够从弱标签中学习并实现像素级的精确分割。这些方法降低了数据标注的成本和门槛,使深度学习在工业瑕疵检测中的落地更具可行性和经济性。系统稳定性需要在不同环境条件下进行验证。南通篦冷机工况瑕疵检测系统技术参数
这些系统生成的数据可以被收集和分析,用于追溯问题根源并优化生产工艺。南京榨菜包瑕疵检测系统案例
深度学习瑕疵检测系统通常采用几种主流的网络架构。在分类任务中,如判断一个产品图像整体是否合格,会使用ResNet、VGG等图像分类网络。更常见且更具价值的是定位与分割任务,这就需要用到更复杂的模型。例如,基于区域建议的Faster R-CNN或单阶段检测器YOLO、SSD,能够以边界框的形式精细定位缺陷所在。而语义分割网络如U-Net、DeepLab,则能在像素级别勾勒出缺陷的具体形状,这对于分析裂纹的延伸路径或污渍的精确面积至关重要。这些模型的训练依赖于大量精确标注的数据,但工业场景中获取大规模、均衡的缺陷样本集本身就是一个巨大挑战,因为合格品远多于次品。为此,数据增强技术(如旋转、裁剪、添加噪声)、生成对抗网络(GAN)合成缺陷数据,以及小样本学习、迁移学习等方法被研究与应用。此外,将深度学习模型部署到实际产线还面临实时性(推理速度必须跟上产线节拍)、嵌入式设备资源限制、模型可解释性(需要知道模型为何做出某个判断,尤其在制造领域)以及持续在线学习(适应生产过程中的缓慢漂移)等一系列工程化挑战,这些正是当前研发的前沿。南京榨菜包瑕疵检测系统案例
与瑕疵检测系统相关的文章

天津铅酸电池瑕疵检测系统
- 苏州篦冷机工况瑕疵检测系统定制价格 2026-01-23
- 广东密封盖瑕疵检测系统性能 2026-01-23
- 无锡线扫激光瑕疵检测系统按需定制 2026-01-23
- 杭州线扫激光瑕疵检测系统供应商 2026-01-22
- 上海木材瑕疵检测系统定制价格 2026-01-22
- 盐城线扫激光瑕疵检测系统趋势 2026-01-22
- 淮安电池瑕疵检测系统服务价格 2026-01-22
- 山东铅板瑕疵检测系统技术参数 2026-01-22
- 扬州电池瑕疵检测系统趋势 2026-01-21
- 四川线扫激光瑕疵检测系统用途 2026-01-21
- 安徽铅酸电池瑕疵检测系统案例 2026-01-21
- 安徽篦冷机工况瑕疵检测系统售价 2026-01-21
与瑕疵检测系统相关的产品


与瑕疵检测系统相关的新闻
-
无锡电池瑕疵检测系统趋势 2026-01-21 23:02:06瑕疵检测的应用远不止电子行业。在纺织业,系统能实时检测布匹的断经、纬疵、污渍、色差、孔洞等,速度可达每分钟数百米,并通过深度学习识别复杂的纹理瑕疵。在金属加工(如钢板、铝箔、汽车板)中,系统检测裂纹、凹坑、辊印、锈斑,并与自动分级系统联动。在锂电池生产中,极片涂布的一致性、隔膜的瑕疵、电芯的封装密封...
-
南通密封盖瑕疵检测系统 2026-01-21 00:12:10随着产品结构的日益复杂和精度要求的不断提升,凭2D图像信息已无法满足所有检测需求。3D视觉技术在瑕疵检测中的应用正迅速增长。通过激光三角测量、结构光或飞行时间(ToF)等原理,3D传感器能快速获取物体表面的三维点云数据。这带来了极大的优势:它可以直接测量高度、平面度、共面性、体积等尺寸信息,不受物体...
-
上海铅酸电池瑕疵检测系统 2026-01-21 11:01:36瑕疵检测的应用远不止电子行业。在纺织业,系统能实时检测布匹的断经、纬疵、污渍、色差、孔洞等,速度可达每分钟数百米,并通过深度学习识别复杂的纹理瑕疵。在金属加工(如钢板、铝箔、汽车板)中,系统检测裂纹、凹坑、辊印、锈斑,并与自动分级系统联动。在锂电池生产中,极片涂布的一致性、隔膜的瑕疵、电芯的封装密封...
-
苏州传送带跑偏瑕疵检测系统供应商 2026-01-21 09:01:34系统的硬件是确保图像质量的基础,直接决定了检测能力的上限。成像单元中,工业相机的选择(面阵或线阵)取决于检测速度与精度要求;镜头的光学分辨率、景深和畸变控制至关重要;而光源方案的设计更是“灵魂”所在,其目的是创造比较好的对比度,使瑕疵“无处遁形”。例如,对透明材料的气泡检测常用背光,对表面划痕采用低...
与瑕疵检测系统相关的问题
新闻资讯
产品推荐
-
江西压装机定制机器视觉检测服务处理方法
2026-01-27 -

上海压装机定制机器视觉检测服务性能
2026-01-26 -

天津电池片阵列排布定制机器视觉检测服务供应商
2026-01-26 -
广东密封盖定制机器视觉检测服务售价
2026-01-26 -
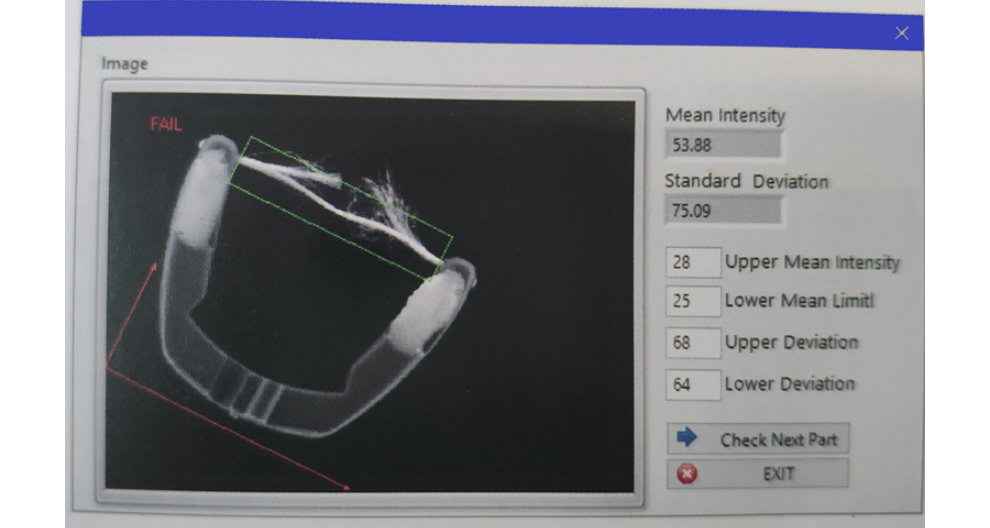
北京冲网定制机器视觉检测服务售价
2026-01-26 -

浙江铅板定制机器视觉检测服务性能
2026-01-26 -

电池片阵列排布定制机器视觉检测服务供应商
2026-01-26 -
广东榨菜包定制机器视觉检测服务处理方法
2026-01-26 -

北京电池定制机器视觉检测服务优势
2026-01-26